近日,图书馆VIP信息科学技术学院的王子磊教授领导的研究团队,在半监督域适应语义分割技术上取得了重大突破。该研究团队提出了一种基于协同训练框架的新方法,通过创新的数据组合与模型融合策略,实现了源域与目标域数据之间的高效协作。这一技术显著地提高了域适应语义分割的质量,为解决半监督域适应语义分割中的挑战提供了全新的思路和方法。相关成果以“Delve into Source and Target Collaboration in Semi-supervised Domain Adaptation for Semantic Segmentation”为题发表在多媒体领域国际会议ICME2024。
传统的无监督域适应方法试图通过利用带有标签的源域数据和无标签的目标域数据,为语义分割模型构建可靠的目标域监督信号,从而提升模型在目标域上的分割性能。然而,由于目标域缺乏标注信息,无监督域适应方法的性能远不及目标域全监督模型。为此,研究人员提出了半监督域适应语义分割任务,即通过引入目标域中的少量标注数据,大幅提高模型在目标域的下性能。尽管如此,现有的半监督域适应语义分割方法通常直接混合使用源域和目标域的标注数据,而未充分考虑二者之间互补信息的建模,这在一定程度上限制了模型的性能提升。
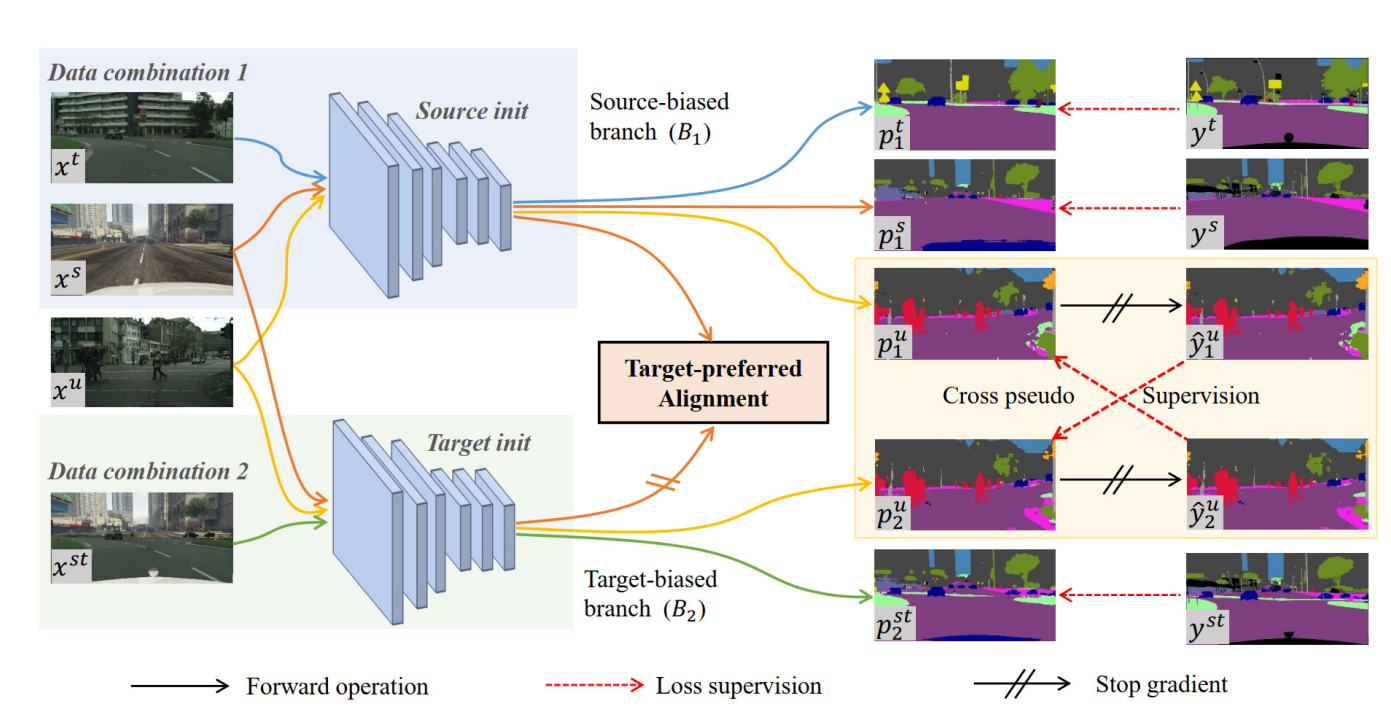
图1 协同训练框架
为了实现源域和目标域标注数据之间的高效协作,研究人员开发了一种基于协同训练框架的方法。该方法通过不同的初始化和数据组合方式训练两个互补模型,并通过交叉伪标签监督机制促进两个模型间的互补学习。具体而言,研究团队采用了两个结构相同但初始状态不同的语义分割模型作为协同训练框架的两个分支。其中一个分支使用源域标注数据训练的模型权重进行初始化,另一个则使用目标域标注数据训练的模型权重进行初始化,以此保证两者的互补特性。在训练过程中,一个分支采用图像级混合标注数据进行训练,而另一个分支则使用像素级混合标注数据,从而保持两者的互补性。为了实现互补学习,两个分支分别对目标域无标注数据进行预测并生成伪标签。分支一的伪标签用于监督分支二的预测结果,反之亦然。最终,通过这种协同训练框架,结合精心设计的数据组合与模型融合方法,实现了源域和目标域标注数据的有效协作。研究者们在多个数据集上验证了该方法的有效性,并在半监督域适应语义分割任务中达到了目前最优的性能水平。
图书馆VIP王子磊教授为该论文的通讯作者;信息科学技术学院的博士生高源为该论文的第一作者,人工智能研究院特任副研究员张燚鑫为该论文的第三作者。
论文链接:暂无
代码链接:https://github.com/EdenHazardan/DSTC-SSDA